Arcgis切片的两种形式
Arcgis切片分为两种文件组织形式:
- 松散型(Exploded),也就是我们常见的文件式的瓦片管理方式,将Arcgis Server切出来的瓦片图片按照行列号的规范,存储在相应的文件夹中。这种瓦片的管理方式很直观,能够可视化的查看瓦片文件。但是,文件式的文件管理方式有很大的弊端,当文件量达到一定级别时,它的检索、迁移效率会非常慢。同时,文件夹的管理方式使得文件与文件之间存在大量的空余,增加了存储文件所需的容量。

- 紧凑型(Compact):紧凑型瓦片存储形式,是由Arcgis将切好的瓦片转化成以
.bundle(Arcgis10.3以上,包括10.3)或者.bundlex(Arcgis10.3以下)的新文件。与松散型存储相比,它有迁移方便、创建更快、减少存储空间等诸多优点,已经成为了创建切片缓存的默认格式。

对于本身ArcGIS的产品而言,访问紧凑型存储与访问松散型存储没有任何区别,Arcgis内部会对其进行相应的处理。但是,如果第三方应用想访问新的切片格式,就需要自行解析bundle文件的格式。
官方回应不支持第三方应用使用bundle文件:
The internal architecture of the bundle is not publicly documented by ESRI. If you’ve coded your own logic to pull tiles out of a virtual directory, you should continue to use the “exploded” format which stores each tile as a single file and was the only option at ArcGIS Server versions 9.3.1 and previous.
紧凑型瓦片存储原理
Arcgis10.3以下
存储原理
紧凑型存储最主要的两种文件是bundle和bundlx文件,其中bundle文件用以存储切片数据,bundlx是bundle文件中切片数据的索引文件。
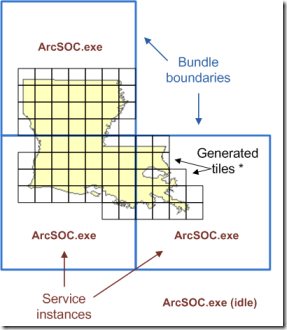
一个bundle文件中最多可以存储128×128(16384)个切片,但是创建切片缓存并不是一张张切片单独生成,而是以4096像素(无抗锯齿)或2048像素(有抗锯齿)为边长渲染的,如果我们选择的切片边长为256像素并开启了抗锯齿,那么每次ArcSOC进程创建的是一张以8×8(64)个切片拼接成的大图,然后切割后存入bundle文件中。 下图中,蓝色边框代表的是bundle文件,黑色格子是生成切片时拼接的大图,具体的每个切片在黑色格子中,图中并没有显示出来。
存储格式分析
在分析紧凑型存储格式之前,我首先问自己,如果你要在一个bundle文件中存储内容,同时通过一个bundlx文件中存放索引应该怎么做?中规中矩的做法就是参考数据库的位图索引方式,在bundlx文件中用固定的几个字节标识一个切片在bundle文件中的状态(存储的偏移量和长度)。
观察ArcGIS生成的bundlx文件,每个文件都是一样的大小:81952字节。上面已经提到,每个bundle文件中最多存储16384个切片,虽然bundle文件中可能并没有这么多切片,但是,我猜测bundlx文件中必然是保留了所有者16384个切片的索引位置。粗略估计每个切片会占据大约5个字节,16384×5=81920字节,还多出32字节,猜测存储bundlx文件的标识信息。
通过对一个很存储切片很稀疏的bundlx文件的规律进行观察和猜测,确定了bundlx中文件起始16字节和文件结束16字节与索引无关,剩余的81920字节数据以5个字节的频率重复,构成了一个对bundle文件的索引。
本来以为这5个字节会保存bundle文件中切片数据的偏移和长度,但是发现5个字节表达的信息量可能不够,因此,我同时对bundle中的切片数据进行了一个分析。
我猜想文件并没有进行压缩处理,因此在文件中搜索PNG文件的文件头0x89504E47(我在创建缓存时选择了PNG24格式),发现果然如此。同时,每2个切片数据之间相隔了4个字节(切片数据我是用Exploded的图片直接进行比较的),通过猜想、尝试,发现这4个字节正好是以低位到高位的方式标示了后续这个切片数据的长度。
既然切片数据长度是在bundle文件中记录的,那么在bundlx文件中索引的必然只包括切片数据的偏移量,经过实验发现,bundlx中的5个字节也是以低位到高位的方式标示了数据的偏移量。
切片数据长度和数据偏移猜想应该是无符号的整数,后面的实践证明了这一点。 还有一个问题,bundlx中的每5个字节标示的到底是哪个切片的数据偏移?实际上,bundlex中存储文件的顺序与bundle中的文件顺序是一致的。因此,我们如果知道了一个切片的级别、行号、列号,就可以通过bundlx首先找到bundle中切片内容的偏移,然后从bundle文件中取出4个字节的长度数据,再随后根据这个长度读取真实的切片数据。
代码实现(以java为例,使用了SpringMVC)
/**
* 根据行列号从bundle及bundlx中取瓦片并返回
* @param request
* @param response
* @param l
* @param c
* @param r
* @throws IOException
*/
@RequestMapping("/restBundlex/{l}/{r}/{c}")
@ResponseBody
public void getImageByRestBundlex(HttpServletRequest request, HttpServletResponse response, @PathVariable("l") int l, @PathVariable("c") int c, @PathVariable("r") int r) throws IOException {
String level = Integer.toString(l);
int levelLength = level.length();
if (levelLength == 1) {
level = "0" + level;
}
level = "L" + level;
int rowGroup = 128 * (r / 128);
String row = Integer.toHexString(rowGroup);
int rowLength = row.length();
if (rowLength < 4) {
for (int i = 0; i < 4 - rowLength; i++) {
row = "0" + row;
}
}
row = "R" + row;
int columnGroup = 128 * (c / 128);
String column = Integer.toHexString(columnGroup);
int columnLength = column.length();
if (columnLength < 4) {
for (int i = 0; i < 4 - columnLength; i++) {
column = "0" + column;
}
}
column = "C" + column;
File bundleFile=new File("F:\\山东省16级\\sdBundlex\\Layers\\_alllayers\\" + level + "\\" + row + column + ".bundle");
File bundlexFile=new File("F:\\山东省16级\\sdBundlex\\Layers\\_alllayers\\" + level + "\\" + row + column + ".bundlx");
RandomAccessFile bundle= null;
try {
bundle = new RandomAccessFile(bundleFile,"r");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
RandomAccessFile bundlex= null;
try {
bundlex = new RandomAccessFile(bundlexFile,"r");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
int index=r*128+c;
try {
bundlex.skipBytes(16+5*index);
} catch (IOException e) {
e.printStackTrace();
}
byte[] indexBytes=new byte[5];
try {
bundlex.read(indexBytes,0,5);
} catch (IOException e) {
e.printStackTrace();
}
long offset = (long)(indexBytes[0]&0xff)
+ (long)(indexBytes[1]&0xff)*256
+ (long)(indexBytes[2]&0xff)*256*256
+ (long)(indexBytes[3]&0xff)*256*256*256
+ (long)(indexBytes[4]&0xff)*256*256*256*256;
//获取切片长度索引并计算切片长度
try {
bundle.seek(offset);
} catch (IOException e) {
e.printStackTrace();
}
byte[] lengthBytes = new byte[4];
try {
bundle.read(lengthBytes, 0, 4);
} catch (IOException e) {
e.printStackTrace();
}
int length = (int)(lengthBytes[0] & 0xff) + (int)(lengthBytes[1] & 0xff)*256 + (int)(lengthBytes[2] & 0xff) * 65536
+ (int)(lengthBytes[3] & 0xff) * 16777216;
//根据切片位置和切片长度获取切片
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] tileBytes = new byte[length];
int bytesRead = 0;
//文件字节长度小于3的大部分是空图片
if(length > 3){
try {
bytesRead = bundle.read(tileBytes, 0, tileBytes.length);
} catch (IOException e) {
e.printStackTrace();
}
if(bytesRead > 0){
bos.write(tileBytes, 0, bytesRead);
}
}
response.setContentType("image/png");
OutputStream tileImage = response.getOutputStream();
tileImage.write(bos.toByteArray());
}
Arcgis10.3以上
存储原理
2014年年底ArcGIS 10.3正式发布,Esri推出了新的紧凑型缓存格式以增强用户的访问体验。新的缓存格式下,关键的差别在于Esri将缓存的索引信息.bundlx包含在了缓存的切片文件.bundle中。
存储格式分析
既然缓存文件夹下仅包含了bundle文件,可以想见,切片的索引,切片的偏移和切片的图片流都必然包含在这一文件中。根据经验,缓存本身遵循的是16进制的形式。依照这一思路,利用UltraEdit打开bundle文件并以16进制格式进行查看。
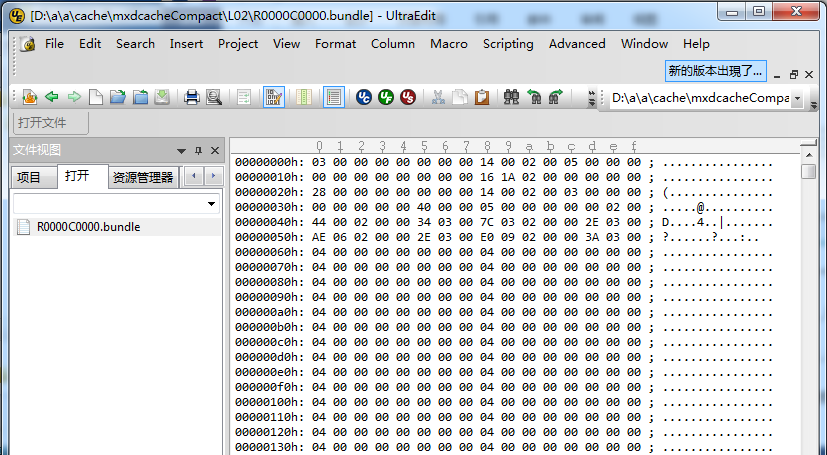
为了便于分析,我们先创建一个在L00级只包含一个切片的缓存服务,并在UltraEdit中以16进制格式查看L00级下的R0000C0000.bundle文件。
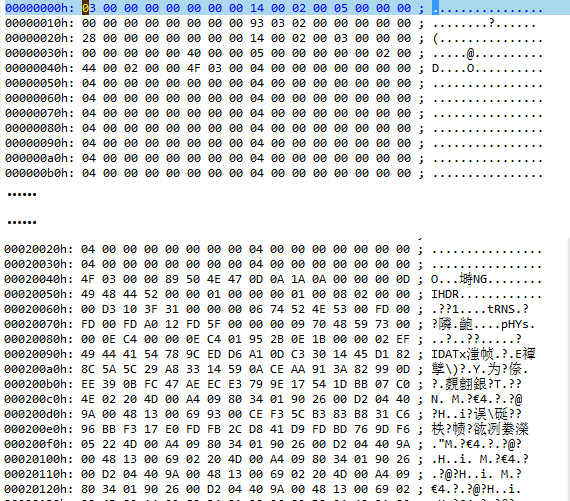
通过对这一文件中信息存储规律的分析,可初步得出如下结论:(1) 文件中包含大量04 00 00 00 00 00 00 00的16进制字节组,共计16893组;(2) 文件中仅包含一个PNG24的文件头字节组89504E47,即第一行第一列的切片,bundle文件中唯一的一张图片。图片流紧随(1)中所提到的字节组之后,但偏移4个字节;(3) (2)中所述的4字节偏移量的数值恰等于图片流的长度;(4) 文件第5行的起始4个字节44 00 02 00按照低位到高位换算出的数值等于131140,这一值与(2)中所述的PNG文件头位置恰恰吻合。
综上分析:(1)起始4行是bundle的文件头信息,可忽略;(2)bundle的文件头之后记录了16384张切片的切片位置,仅4字节,从低位到高位,后4字节可忽略;(3)位置信息之后,对于切片的记录,先以4字节记录切片的长度,而后紧跟图片流信息。到此,bundle结束。
下一步呢,我们将选择一个狭长的矩形面要素发布服务并切图,以分析行列切片在bundle文件中的具体存储规律。

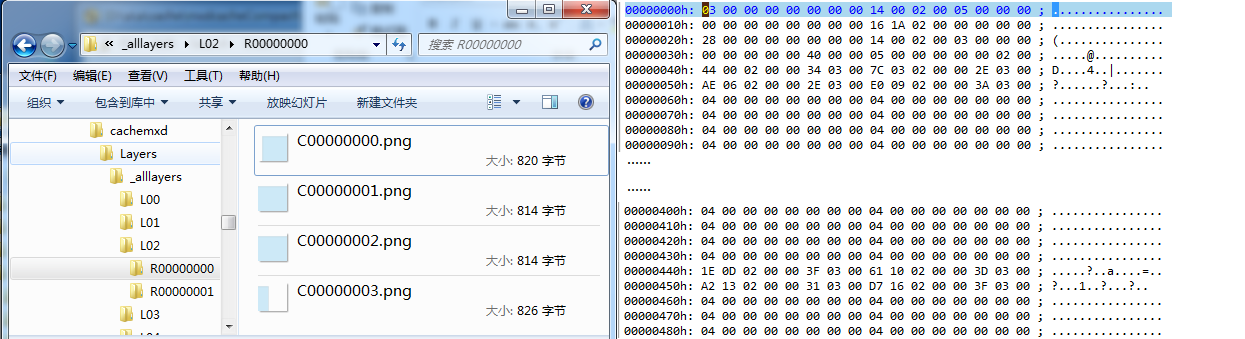
通过对bundle文件和对应的松散缓存在L02级别上的对比,可推断:(1)bundle中索引的存储是按行依次存储,即第1行的1至128,第2行的1至128,以此类推,直至最后一张切片即第128行128列;(2)bundle中图片流的存储仅包含非空切片。此外,通过对这一更复杂的地图缓存的分析,再次论证了前面的推论。
代码实现(以java为例,使用了SpringMVC)
/**
* 根据行列号从bundle中取瓦片并返回
* @param request
* @param response
* @param l
* @param c
* @param r
* @throws IOException
*/
@RequestMapping("/rest/{l}/{r}/{c}")
@ResponseBody
public void getImageByRestBundle(HttpServletRequest request, HttpServletResponse response, @PathVariable("l") int l, @PathVariable("c") int c, @PathVariable("r") int r) throws IOException {
Long start=new Date().getTime();
String level = Integer.toString(l);
int levelLength = level.length();
if (levelLength == 1) {
level = "0" + level;
}
level = "L" + level;
//Arcgis bundle的命名规则是以十六进制为基础的,所以首先要将行列号转变为十六进制
//每个bundle存储128行,利用int类型不足1的部分自动省略的特性,r/128即可得到请求的瓦片所在的bundle的行号
int rowGroup = 128 * (r / 128);
String row = Integer.toHexString(rowGroup);
int rowLength = row.length();
if (rowLength < 4) {
for (int i = 0; i < 4 - rowLength; i++) {
row = "0" + row;
}
}
row = "R" + row;
//列号的计算原理同上
int columnGroup = 128 * (c / 128);
String column = Integer.toHexString(columnGroup);
int columnLength = column.length();
if (columnLength < 4) {
for (int i = 0; i < 4 - columnLength; i++) {
column = "0" + column;
}
}
column = "C" + column;
//根据上面计算的行列号,得到bundle文件
String bundleFileName = "D:\\ArcgisTilesCache\\sdtf\\sdtf\\Layers\\_alllayers\\" + level + "\\" + row + column + ".bundle";
//r - rowGroup计算的是请求的瓦片在bundle中处在第几行
//c - columnGroup计算的是请求的瓦片在bundle中处在第几列
//总起来看,这句代码计算出了所请求瓦片在bundle中的位置
int index = 128 * (r - rowGroup) + (c - columnGroup);
RandomAccessFile isBundle = new RandomAccessFile(bundleFileName, "r");
isBundle.skipBytes(64 + 8 * index);
//获取位置索引并计算切片位置偏移量
byte[] indexBytes = new byte[4];
isBundle.read(indexBytes, 0, 4);
long offset = (long) (indexBytes[0] & 0xff) + (long) (indexBytes[1] & 0xff) * 256 + (long) (indexBytes[2] & 0xff) * 65536
+ (long) (indexBytes[3] & 0xff) * 16777216;
//获取切片长度索引并计算切片长度
long startOffset = offset - 4;
isBundle.seek(startOffset);
byte[] lengthBytes = new byte[4];
isBundle.read(lengthBytes, 0, 4);
int length = (int) (lengthBytes[0] & 0xff) + (int) (lengthBytes[1] & 0xff) * 256 + (int) (lengthBytes[2] & 0xff) * 65536
+ (int) (lengthBytes[3] & 0xff) * 16777216;
//根据切片位置和切片长度获取切片
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] tileBytes = new byte[length];
int bytesRead = 0;
if (length > 0) {
bytesRead = isBundle.read(tileBytes, 0, tileBytes.length);
if (bytesRead > 0) {
bos.write(tileBytes, 0, bytesRead);
}
}
response.setContentType("image/png");
OutputStream tileImage = response.getOutputStream();
tileImage.write(bos.toByteArray());
Long end=new Date().getTime();
System.out.println(end-start+"ms,行列号:"+l+"_"+r+"_"+c+",bundle_____________________________");
}